지난번에는 파이썬에서 웹 크롤링 하기 위해
셋팅을 하고,
제목을 가져오는 방법을 정리해보았습니다.
그래서 오늘은 파이썬에서 웹크롤링하기 2탄으로
태그와 클래스 값을 이용하여
데이터를 가져오는 방법을
정리해보도록 하겠습니다.
저는 지난번처럼 daum 사이트를 이용하여
웹 크롤링 실습일 진행해 보도록 하겠습니다.
브라우저는 크롬을 기준으로 진행하였습니다.
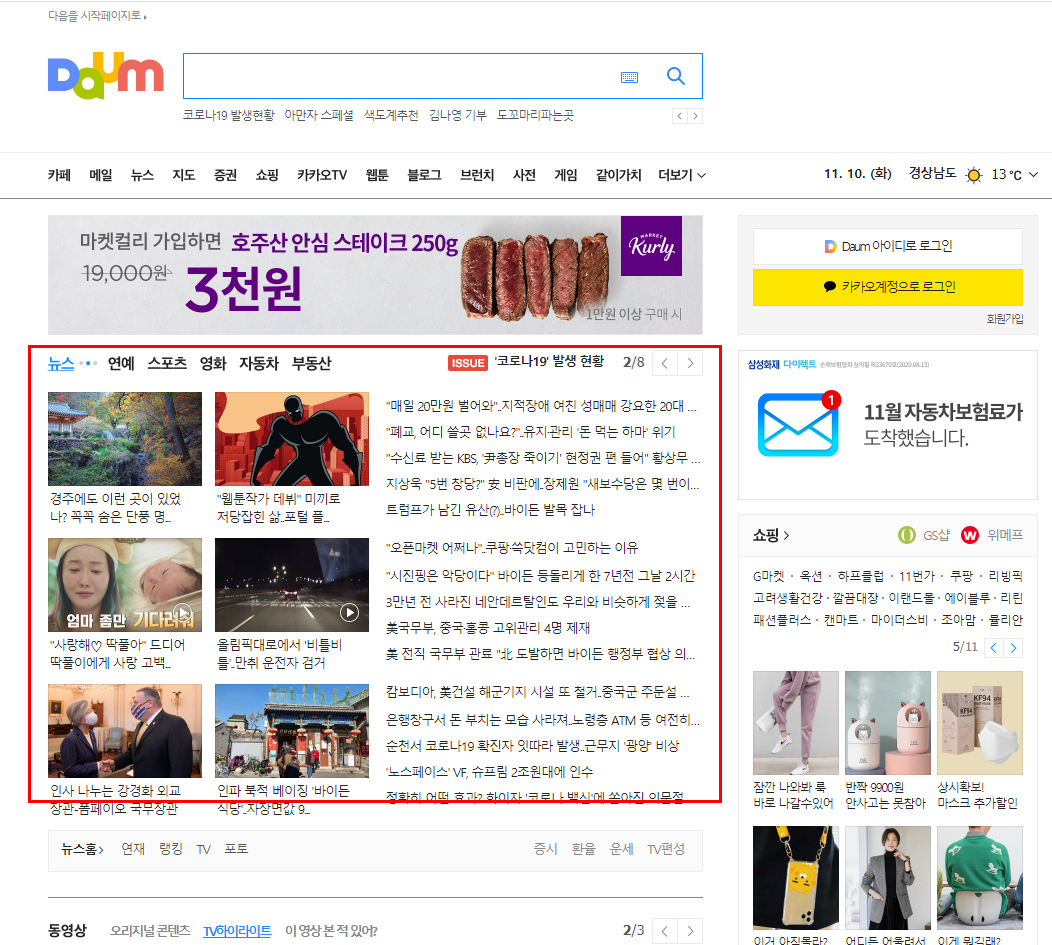
위처럼 기사 부분이 있습니다.
이런 기사 부분의 데이터를 가져오는 것을
목표로 해서
오늘 정리를 해보도록 하겠습니다.
우선, 기사를 가져오기 위해서는
태그와 클래스 값 등을 확인해야 합니다.
그래서 저는 F12를 눌러 개발자도구를 열었습니다.

개발자도구에서는 원하는 위치의
html이 무엇인지 찾는 것이 있습니다.
개발자도구 맨 왼쪽 위에 보시면
마우스포인터 모양의 아이콘이 있습니다.
그걸 클릭해서 활성화 시킨 상태에서 원하는 부분을 누르면
해당 위치의 html 부분이 열리게 됩니다.

위 빨간 네모 부분을 누르면 활성화가 되어 있습니다.
그리고 그 상태에서 원하는 부분을 클릭해주시면 되십니다.
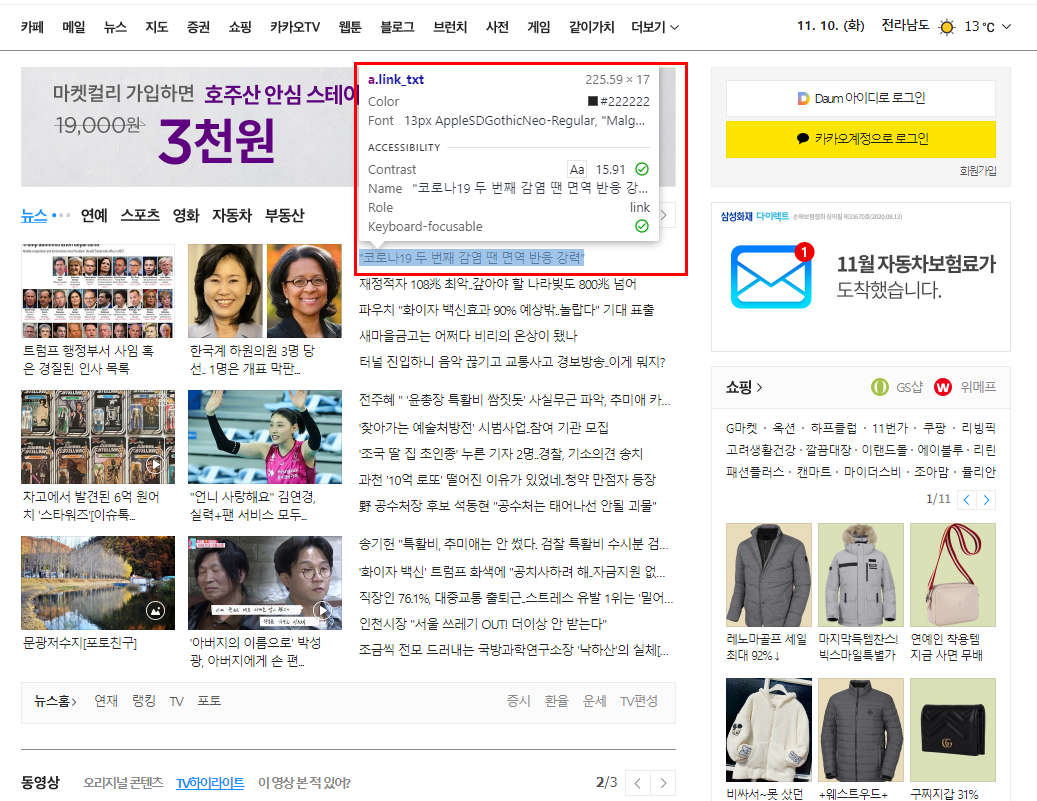
위처럼 마우스가 가게 되면
간단한 정보가 나오게 됩니다.
그리고 클릭을 하게 되면 해당 위치로 개발자도구에서
이동을 하게 됩니다.

위처럼 이동을 하게 되는 것입니다.
위 화면을 보시면 아시겠지만
해당 부분의 태그는 a태그를 사용하였습니다.
그리고 class는 link_txt로 된 것을
확인할 수 있습니다.
그러면 이제 a태그에서 class는 link_txt인 것에 대해서
값을 가져오는 방법을
정리해보도록 하겠습니다.
저는 아래처럼 코딩을 하였습니다.
import requests
from bs4 import BeautifulSoup
#reqeusts 라이브러리 이용 가져오기
htmls = requests.get('https://www.daum.net/')
#BeautifulSoup 이용 파싱하기
bs = BeautifulSoup(htmls.content, 'html.parser')
#html 태그와 class를 이용하여 데이터 추출하기
Search_data = bs.find('a', class_='link_txt')
print(Search_data)
위와 같이 소스를 작성하였습니다.
find에서 a태그를 찾고,
class는 link_txt인 값을 찾으라는 것입니다.

위처럼 코딩을 하였고
실행을 하게 되면
결과는 아래와 같이 나오게 됩니다.

위처럼 나오게 되는 것을
확인할 수 있습니다.
이 닦다가 피났을 때는 더 꼼꼼히 닦으라는
기사를 가져오게 되었네요.
위치를 찾아보니 아래위치에 이런 기사가 있었네요.
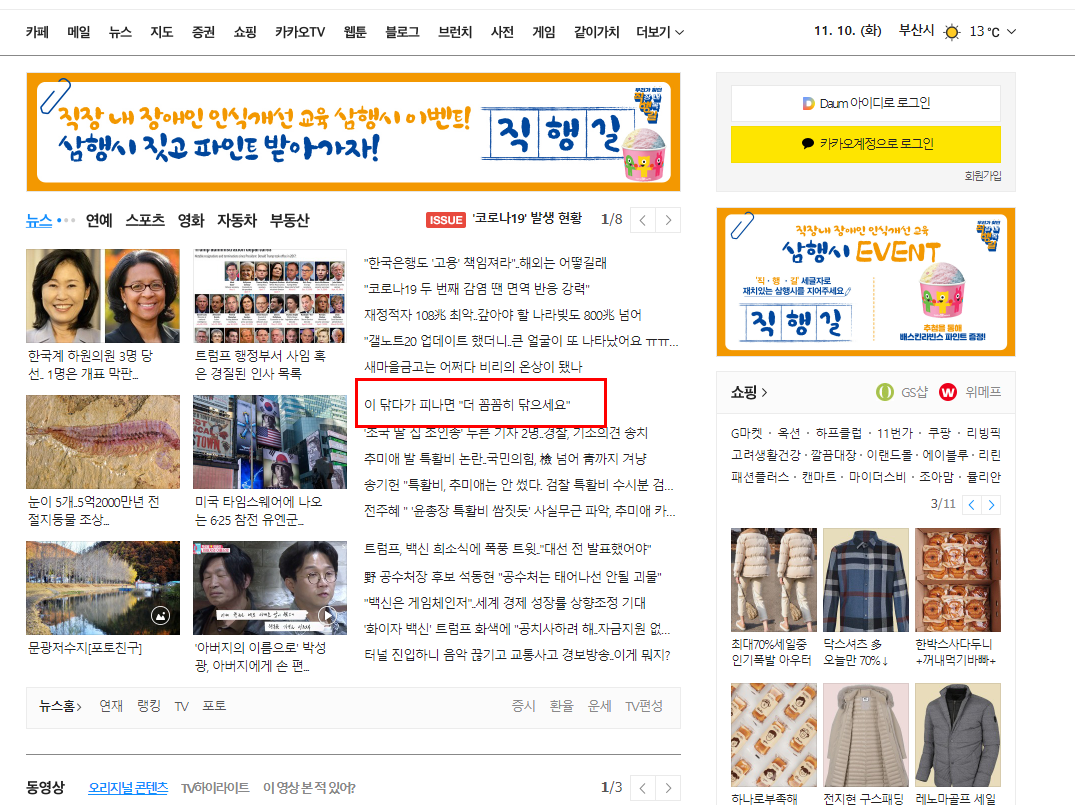
이렇게 하나의 값을 가져오게 되는 것입니다.
저런 기사들이 모두 같은 a태그에 link_txt 클래스를 사용할 것이기 때문에
이 중 하나를 가져오게 된 것입니다.
그러면은 이번에는
이 중에 저 기사의 제목 부분이라고 해야 하나?
꼼꼼히 닦으라는,
고객에게 보여지는 부분만 가져와 보도록 하겠습니다.
저는 아래와 같이 코딩을 하였습니다.
import requests
from bs4 import BeautifulSoup
#reqeusts 라이브러리 이용 가져오기
htmls = requests.get('https://www.daum.net/')
#BeautifulSoup 이용 파싱하기
bs = BeautifulSoup(htmls.content, 'html.parser')
#html 태그와 class를 이용하여 데이터 추출하기
Search_data = bs.find('a', class_='link_txt')
print(Search_data)
print(Search_data.string)
print(Search_data.get_text())
위 소스를 보시게 되면
string과 get_text() 함수 이렇게 2라인이 더 추가가 되었습니다.
이 두개의 방법은 모두 같은 내용을 가져오게 되는 것입니다.
string으로 문자 부분을 가져올 수도 있고,
get_text() 함수를 이용하여 문자를 가져올 수도 있습니다.

위처럼 코딩을 하였고
실행을 하게 되면 결과는 아래와 같이 됩니다.

위처럼 나오게 됩니다.
빨간색 네모친 텍스트 부분을 가지고와서
출력을 해준 것입니다.
위의 소스에서는 "class_= " 명령어를 이용하여
class이름을 지정해 주었습니다.
하지만 이 부분은 생략이 가능한 부분입니다.
아래처럼 생략을 하고 코딩도 가능합니다.
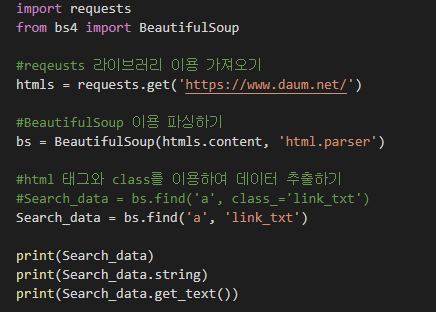
import requests
from bs4 import BeautifulSoup
#reqeusts 라이브러리 이용 가져오기
htmls = requests.get('https://www.daum.net/')
#BeautifulSoup 이용 파싱하기
bs = BeautifulSoup(htmls.content, 'html.parser')
#html 태그와 class를 이용하여 데이터 추출하기
#Search_data = bs.find('a', class_='link_txt')
Search_data = bs.find('a', 'link_txt')
print(Search_data)
print(Search_data.string)
print(Search_data.get_text())위 소스를 보시면 기존에 find에서 class_= 명령어가 있던 라인을
주석처리 하였습니다.
그리고 class_= 을 생략한 것을
새로 입력해 놓았습니다.

이 부분만 차이가 있고,
그 외에는 모두 동일한 소스인 것입니다.
위처럼 코딩을 하였고,
실행을 해보았습니다.
그러면 결과는 아래처럼 나오게 됩니다.

위처럼 나오게 되는 것입니다.
기사의 내용은 랜딩도 되고,
하나를 가져오는 것이기 때문에
좀 다를수 있습니다.
계속 이 닦으라고 나오더니
이번에는 국가안보 어쩌구 나오네요.
이건 태그와 클래스 값을 이용하여
값을 가져오는 것이다 보니
그럴 수 있음은 이해 부탁드립니다.
오늘은 파이썬에서 웹크롤링하기 2탄이였습니다.
태그와 클래스 값을 이용해서
특정 위치, 원하는 태그의 원하는 클래스로 설정된
텍스트 내용을 가져오는 방법을
정리해보았습니다.
공부를 하면서 하다보니 진행이 느린건
어쩔 수 없네요.
어쨌든 제가 직접 해보고
문제가 없는 것들만 올리기 때문에
어떻게 보면 느려도 정확하다고 할 수 있을거 같기도 하네요.
하지만 그래도 틀릴 수 있으니
틀린점이 있다면,
해당 부분은 지적 부탁드립니다.
이상으로 python에서 웹크롤링하기 2탄
태그와 클래스 값으로 데이터 가져오기였습니다~~~
소스코드 복사가 안된다면
sagittariusof85s.tistory.com/140
[컴퓨터관리]크롬브라우저에서 마우스우클릭 드래그 방지 해제하기
요즘은 많은 인터넷 사이트들이 마우스 우클릭 및 드래그를 막아놓고 있습니다. 불펌이나 복사 등을 막기 위해서 하는 경우가 대부분입니다. 그렇지만 이런 사이트에서도 드래그 및 우클릭을
sagittariusof85s.tistory.com
위 주소 참고 부탁드립니다~

파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'컴퓨터관련 > Python' 카테고리의 다른 글
| python에서의 bytes형(바이트형) (2) | 2020.12.08 |
|---|---|
| python에서 requests로 Get, Post API 통신하기 (1) | 2020.11.25 |
| Python에서 BeautifulSoup 이용 웹크롤링하기 1탄 제목 가져오기 (0) | 2020.11.11 |
| python에서 인자값 입력받기 (0) | 2020.10.22 |
| python에서 산술연산자와 산술함수 (0) | 2020.08.06 |



